The Guardian decided to censor the Letter to America from Osama bin Laden, as it was going viral upon being rediscovered in the context of the current Israel-Hamas conflict in Gaza.


credit:
The Guardian decided to censor the Letter to America from Osama bin Laden, as it was going viral upon being rediscovered in the context of the current Israel-Hamas conflict in Gaza.
credit:
The “move to Somalia” trope shows a deep misunderstanding of what is required to bring about a good and orderly society. [See original tweet thread]
Whether society is mired in chaos, violence, and crime or thriving in peace and prosperity depends entirely on the morality of its individuals. It is not a function of government or lack thereof. One need only look at urban areas in the US with the most stringent law enforcement to see the worst crime. Whereas, rural areas with the least enforcement are the most crime-free. The difference is in the principled self-regulation of behavior of the individuals.
Whether society has oppressive government rules and enforcement or freedom only affects whether optimal conditions are provided for morally-behaved individuals (already at peace and refraining from violence and crime) to flourish and thrive. Liberty enables human flourishing. However, no degree of heavy-handed government force can subdue a chaotic, violent, and criminal population. Indeed that is what Somalia demonstrates.
Today, on July 4, Federal Judge Terry Doughty finds the government likely violated the First Amendment by conspiring with Big Tech in a “far-reaching and widespread censorship campaign.” The judge grants a preliminary injunction blocking the DOJ, FBI, and DHS from working with technology companies to censor content. The “Ministry of Truth” style censorship is now prohibited.
[Updated July 5, 2023]
[Updated July 6, 2023]
[Updated July 7, 2023]
[Updated July 10, 2023]
[updated July 14, 2023]
I was reading this article on the behavior of neutron stars and black holes being very similar with regard to accretion. This reminded me of a hypothesis I’ve had for a very long time. I will state it below.
My hypothesis is that the compact object at the interior of the black hole is the same stuff as a high mass neutron star, whether you call that a quark star or whatever. The only difference is that the event horizon grows to engulf the entire object. This hypothesis may also exclude the existence of a singularity, although I’m not confident about that, as I will also explain.
When a neutron star accretes matter gradually, eventually there is enough mass to become a black hole. At that critical moment, is there a violent event? A non-violent event would suggest the interior of the black hole is unchanged from the neutron star that was its progenitor.
If the gradual accretion scenario is non-violent, it suggests there is no state change in the compact object itself. It is only the curvature of spacetime that changes, as the Swartzschild radius grows to engulf the entire object. A non-event suggests the nature of the compact object is unchanged. There is no release of energy.
The Swartzschild radius > 0 for a neutron star. Its interior within that radius already is subject to black hole spacetime curvatures without evidence of a singularity. Therefore, I disbelieve a singularity exists at all.
This also supports the idea that black holes and neutron stars are made of the same stuff. The growth of the Swartzschild radius is gradual with accretion. There isn’t a continuous series of violent events as the neutron star gains mass. Or is there? Maybe that explains the violent outbursts observed from neutron stars. This is known as a starquake. The neutron star compacting its material into a lower energy state. They think it is a surface phenomenon. I’m not so sure.
On the topic of a singularity, if the Swartzschild radius is already > 0, that means the innermost core of a neutron star is already a black hole. Is there any evidence of a singularity? What would such evidence look like to an outside observer? I read somewhere that the singularity is not necessarily a point in space, but can be thought of as a point in time. My mind struggles to imagine what that would mean. Given information cannot escape the event horizon except as Hawking radiation, we shouldn’t be able to observe any evidence of what is inside. Therefore, we cannot be certain.
Have I talked myself out of my hypothesis? No. If the final transition from neutron star to black hole is non-violent, I think it supports my claim. My hypothesis is also consistent with the current accepted explanation of starquake as a surface phenomenon. However, if a starquake results from gradual growth of the Swartzschild radius within a neutron star, I think that would falsify my claim. High energy events from the interior would suggest that there is a change in state of the stuff inside the neutron star.
Facebook’s renaming as Meta brought attention to the rise of the metaverse. I would like to explore how to think about the metaverse and related technologies.
the “metaverse” is a hypothetical iteration of the Internet as a single, universal, and immersive virtual world that is facilitated by the use of virtual reality (VR) and augmented reality (AR) headsets.
https://en.wikipedia.org/wiki/Metaverse
This description identifies VR and AR headsets as an essential feature. However, I believe headsets are extraneous. I contend that headsets are not worth pursuing for the general public. What is essential is the evolution to the next generation of the Internet to become a single, universal, and immersive virtual world.
Today’s most important Internet technologies are known as the World Wide Web (WWW). The next generation of the Internet would be the third. The first generation delivered mostly static hypertext content from content producers to consumers. Today’s second generation services and platforms enable users to create content and distribute that content to an audience.
Ethereum co-founder Gavin Wood coined the term “Web3” for the third generation. It envisions the WWW to be decentralized with blockchain technologies. Web3 would enable token-based economics.
I have a different perspective on Web3. To expand on this perspective, I wrote What do we want from Web3? In particular, I do not see Ethereum being a suitable basis for Web3. To fully realize the goals, Web3 will require additional innovations and decentralized technologies that are general-purpose and not vulnerable.
The metaverse has even attracted the attention of the World Economic Forum (WEF). They have published a document called Demystifying the Consumer Metaverse.
The World Economic Forum has assembled a global, multi-sector working group of over 150 experts to co-design and guide this initiative. The hope is that this will lead to cross-sector global cooperation and the creation of a human-first metaverse. The metaverse has the potential to be a game-changer, but it must be developed in a way that is inclusive, equitable and safe for everyone.
We can see from their own language that they intend to appoint their own people to co-opt the technology. They wish to set the direction for the technological innovations toward advancing their own agenda. That agenda seeks to design a better world, one in which liberty is curtailed, autonomy is surrendered, choices are restricted, and power is concentrated in anointed leaders.
For the WWW to be more universal and immersive, a user should not have to login separately using distinct account credentials, when navigating to each site. The user should have a smooth and seamless experience. Digital identity is an essential element of continuity. A user can specify preferences and localization once, and have sites be personalized everywhere.
In today’s Web2, ad networks use crude techniques to attach an identity to users. IP addresses, tracking cookies, and browser fingerprinting are typical approaches.
Once users have a digital identity that is universally recognized, users can then be tracked. Ad tracking is a creepy annoyance. However, the most serious danger will be surveillance tied to authoritarian control.
The US government regulates economic activity by controlling the money and its flow through financial institutions and payment systems. Know Your Customer (KYC) and Anti-Money Laundering (AML) are policies for this control. Currently, such policies rely on verifying a person’s identity using some form of state issued ID, such as a driver’s license or passport.
We can expect the government to seize the opportunity to co-opt digital identity in Web3. A state-issued digital identity would provide a key element for the government to exert authoritarian control. This topic will be addressed later in this article, once we explore other requisite elements.
Digital identity would lead to the loss of anonymity in transactions. KYC and AML policies apply to financial transactions, but every type of transaction (i.e., any online action taken by the user) could be subject to surveillance. Surveillance of consumer behavior has commercial value to corporations. However, the unholy collusion between government and corporations is a hazard for individual rights, as we will expand on below.
Similar to the need for crypto-currency holders to maintain self-custody of their private keys, a person’s digital identity should be protected similarly. This is known as Self-sovereign identity. The owner must be able to control the revocation and re-issuance of their own digital identity. This may be necessary to counter targeted harassment and cancel culture.
More generally, self-sovereign data refers to users maintaining custody and ownership over their own data. Without self-sovereign data, fourth amendment rights against unreasonable search and seizure have been eroded. Law enforcement requests to communications service providers for customer data have been allowed without warrants. Courts have ruled that customers have no reasonable expectation of privacy for records about them kept by service providers. We recover these rights by reorganizing services and Web3 to become decentralized and by allowing customers to take custody over their data.
Moreover, if users can take custody over their own services through self-hosting, they would gain sovereignty over the applications that implement functions against their data. The combination of self-sovereign identity, self-sovereign data, and self-sovereign services protects against deplatforming and third party policy abuse.
A digital representation of a physical object is termed a digital twin. Applications in the metaverse will rely on digital twins to accomplish many things, such as enabling physical objects to be explored and manipulated virtually in ways that are impractical in the real world.
Physical assets will need to be tokenized to identify them. Web3 includes the Non-Fungible Token (NFT). A NFT is a digital identifier denoting authenticity or ownership.
Once assets have digital identity, it becomes easier to track them for the purpose of monetizing them. One way is to attach digital services to those physical assets. Subscribing for support, maintenance, and warranty repairs is an example of a service that can be monetized online for physical assets.
The Internet of Things (IoT) goes further by connecting physical assets to the Internet. This enables digital services to make use of or add value to those physical assets. Sensors, cameras, and control systems come to mind as obvious use cases. However, everything imaginable could be enhanced with connectivity to digital services.
Physical asset tokenization leads to the erosion of ownership. Intellectual property rights, such as those attached to embedded software components, are retained by the manufacturer. The consumer is granted only a license to use with limited rights. The consumer has no right to copy that software to other hardware. This protects the software vendor from loss of revenue.
Does the consumer have a right to sell the physical asset to transfer ownership? One would expect that the hardware and its embedded software are considered to be an integrated whole or bundle. Hopefully, the software license is consistent with that.
A digital service connected to the physical asset is remote and distinct. A boundary clearly separates that remote software from the physical asset. There is no presumption of integration. The terms of service would need to be consulted.
Modern software is maintained with bug fixes and enhancements over time. Increasingly common, the vendor charges the consumer a subscription fee for maintenance and support. Does the consumer have the right to continue using the asset without subscribing? Can ownership of the asset be transferred along with its software subscription?
These questions go to the erosion of ownership. Physical things, such as vehicles and farm equipment, are becoming useless hulks without subscriptions to connected digital services and software maintenance. Instead of owning assets, people are subscribing to a license to use. It’s like renting or leasing. According to the WEF’s Agenda 2030, you will own nothing, and you’ll be happy.
Software capabilities are essential to the functioning of equipment and devices. The traditional ownership model of farm equipment, vehicles (i.e., cars and trucks), and mobile phones, is evolving to a model where the end user has a license to use. License terms may restrict the user’s rights to modify, maintain, and transfer that asset.
Traditionally, an owner of an asset expects to be able to repair, modify, or build upon the asset. He can do it himself, or he can contract work out to others. Manufacturers are eroding these rights. They don’t want their software to be tampered with.
Many legislatures are passing Right To Repair acts to preserve some semblance of ownership control over physical assets. However, remote connectivity to digital services may never be brought into the fold.
The relationship between physical assets and digital services, including the metaverse, is fraught. We should think of the metaverse as the landscape in which all future digital services reside. Increasingly, physical assets are connected inextricably to digital services. Thus, the physical world and the metaverse become tied.
Monetization of digital services will be integral to the metaverse. Crypto-currency will be a key technology in Web3 to enable the digital economy. As novel cryptos gain consumer acceptance, you can be certain that governments will take notice.
Government has an interest in controlling money. Fiat money is manipulated by the central bank and their monetary policy. The supply is increased by making loans, which is a means of counterfeiting money. Money-printing dilutes the purchasing power resulting in inflation. The biggest loans are to finance government deficit spending.
Government seeks to gain control by making money programmable. Central Bank Digital Currency (CBDC) is programmable fiat money for this purpose. Control includes regulating who may spend money, when, where, on what, and how much. Authoritarian control will be total.
The Chinese Communist Party (CCP) has implemented a social credit system of authoritarian control. Individuals are assigned a social credit score based on surveillance of their behaviors. Privileges, travel authorization, and access to services may be restricted based on social credit score.
Programmable digital currency will be the perfect tool for authoritarian regimes to control public behavior. With hard cash replaced, no economic activity would escape government surveillance and control. Discrimination and cancel culture will be institutionalized.
Instead of the dystopian future that would follow from a metaverse based on flawed Web3 platforms, we must proceed with caution. Every technology must be scrutinized for vulnerabilities to capture and corruption by centralized powers. Decentralization and self-sovereignty must be paramount.
Avoid crypto-currencies that are not Bitcoin. Shitcoins are all scams. They are all corruptible, already corrupted, or corrupt by design. This is especially true of CBDC (or any crypto that is a candidate).
Disregard the hype. Headsets will never gain broad adoption. People will not tolerate being detached from reality for extended periods. Immersive experiences are valuable. However, people need to be able to multitask. Visiting places in the metaverse must be possible while still remaining engaged with normal activities of daily life and work.
Protect your identity and data. Self-sovereign identity and self-sovereign data are essential. True decentralization is essential. Any Web3 platform that does not honor these principles should be rejected.
The future will be bright, if we refuse to accept technologies that leave us vulnerable. It is early enough in the development of Web3 and the metaverse to reject poor technology choices. As consumers are better informed, they can have an enormous influence on what technologies are developed and adopted. Ethereum’s first mover advantage in Web3 and Meta’s first mover advantage in metaverse should be seen as consequential as MySpace and Friendster were to Web2.
I believe my derivation of Rights from first principles provides the most consistent definition. Let’s see how it holds up in various circumstances, where other formulations fail.
My position on abortion recognizes viability as the existence of an independent person. This is the beginning of a human life’s ability to exist with a mutual recognition of rights.
In the context of criminal justice, a violation of someone else’s rights demonstrates a non-recognition of rights. As a consequence, the violator’s rights may then lose recognition. Under imminent threat of violence, a person may defend themselves or others against the violator. The violator forfeits the right to life through non-recognition. Following the crime, justice may demand incarceration or punishments, as the violator’s rights are diminished. The death penalty is the ultimate retaliatory non-recognition of the violator’s right to life.
The consistency of this definition of rights across abortion, self-defense, criminal justice, and the death penalty strengthens the case for it being correct.
We need conversations about the proper role of violence in civilized society. Intellectual discussion about violence is not incitement.
We are repeatedly reminded that violence is never the answer. It’s the proper message to convey to children at the playground. The principle continues to apply generally to most situations ordinarily. However, with adulthood comes the responsibility to understand the world more deeply. This includes the understanding that the world is not a safe place. Even if one never commits an act of violence, there are those who would initiate force in contravention of norms. Maturity requires nuance.
All rights are derived from the right to life as a human being. That necessarily includes the right to protect that life through self-defense and defense of others. We immediately see a legitimate use of violence for defense.
Mutual defense extends collectively to territories organized into defense pacts. This may be at the level of nation states or military alliances like NATO. Military action to repel foreign invasion is another legitimate use of violence.
In libertarianism, the Non-Aggression Principle (NAP) has primacy. The NAP prohibits the initiation of force.
The philosophy of Objectivism holds that the initiation of force is an evil violation of individual rights against which the government should protect its citizens.
http://wiki.objectivismonline.net/Initiation_of_force
Protection from the initiation of force entails the use of retaliatory force in self-defense and the defense of others. Minarchists believe this to be the government’s only legitimate role—to protect individual rights through the monopoly on retaliatory force wielded through the due process of law.
Guy’s Take #61 – Blockchains, A Square Peg for Round Holes provides this revelatory nugget on the topic of government protecting property rights. A system of state violence is what secures physical things. Digital information, such as NFTs, can never secure anything, because physical security ultimately relies on violence.
Having entrusted government with a monopoly on violence, Robert Malone asks the right question.
Ryan McMaken writes The Constitution Failed. It Secured Neither Peace nor Freedom. This article should remind us of how words on a document do not protect freedom. Protection relies on humans committed to those principles to defend them with violence.
One of the fundamental principles encoded in the Constitution is the Second Amendment, which protects our right to keep and bear arms for the purpose of self-defense and defense of others. Whenever we see foreign governments violate the rights of individuals, Americans lament “if only they had the Second Amendment…”.
The larger purpose of the Second Amendment remains customarily unsaid. It is to empower the people to have the necessary means to mount an armed insurrection to remove a government, when it has fallen into tyranny. The Declaration of Independence was an act of insurrection, which founded the United States of America. The Second Amendment preserves the tradition that brought the country into existence.
What endangers the American people today is the growing apprehension toward being able to discuss what would constitute justifiable use of force, as envisioned by our Founding Fathers in authoring the Second Amendment. The Boston Tea Party suggests that an act of taxation without representation crossed a red line. Absent other examples, that remains our gold standard as a comparable. Has America experienced usurpations and acts of tyranny that far exceed the historical standard? Without a doubt. Have the goal posts moved on where to draw the red line? Without a doubt. However, without the freedom and the intellectual honesty to have that academic conversation, the American people will not know where the red line needs to be. Without a proper basis in rational thought, the danger is that individual Americans may decide unwisely for themselves, and then it will be too late.
Therefore, we should have that discussion sooner than later.
What is the ethical framework for how to respond to the unethical behavior of others? When is it permissible to use retaliatory force?
Something that confounds our reasoning is not having a thought-through ethical framework for how to respond to the unethical behavior of others. This applies to violence, coercion, lying, and other forms of trespassing.
This is why we see widely varying opinions about politics. Most recently we see Sam Harris beclowning himself in support of opposing Trump by any means necessary, including to lie, cheat, and censor. MAGAs see Trump’s actions as justifiable retaliation. Others say how dare he?
Has anyone seen a treatise on the ethics of self-defense and mutual defense (economic, legal, reputational, physical force, etc.)? Seems like a major topic that is given insufficient thought, as people are operating without guidance on such matters. “Cancel culture” emerges.
For example, if public institutions are captured, lying, and coercing, what range of retaliatory behaviors are within the realm of ethical responses that should be employed?
The muddiness of this topic is exemplified by the left’s view of DeSantis being authoritarian in enacting policies that retaliate against corporate power colluding covertly with the federal government and global elites. Whether such actions are considered pro-liberty or authoritarian depends on perspective. This divide is a cold civil war.
Sadly, the ethics of retaliatory force is a topic outside the Overton Window. We are unable to have an intellectual conversation in public, so no one can figure out the red lines, responses, and rules for this cold civil war. Thus, random flailing volatility will abound.
Even Sam Harris invokes self-defense (against an asteroid impact) to justify the actions against Trump. Trump is accused of going against peaceful transfer of power (some calling it an insurrection), after his own Presidency was attacked by the unpeaceful transfer of power, as presaged by text messages between Peter Strzok and Lisa Page. Trump’s term in office was under constant attack by the Russia Collusion Hoax based on the Steele Dossier, the falsified FISA warrant to surveil Carter Page, and impeachment trials.
Here is Sam Harris’ response. https://twitter.com/alexandrosM/status/1560355035149582337?t=CKrEcUpP5HpsyUeawM6JFw&s=19
Retaliation and reciprocity lead to an infinite regress in escalating tit-for-tat retribution. After a while of this back-and-forth, no one can remember who started it, nor the threshold that was a red line crossed. It becomes intractable like the Israel-Palestine conflict, where each side considers the other the aggressor.
After years of chaotic cold civil war, who is going to remember whether America fought against a Russian influence operation abetted by Trump, whether Sam Harris defended the Earth from an asteroid impact (Trump’s fault), or whether Trump fought back against the career bureaucrats and intelligence community aligned against him?
I was not happy with my article Carrier Billing and Micropayments, when I first published it over a year ago. I did not feel that the ideas I was trying to communicate were distilled into a coherent formulation. What follows here is a second attempt at trying to convince Communications Service Providers (CSPs) to stop selling dumb pipes.
Most CSPs are old incumbent carriers with large loyal customer bases, established business models, and products that are substantially unchanged for decades. These enterprises are risk-averse. There is little tolerance for changes that would be disruptive to how business is run.
CSPs are in the business of selling dumb pipes (e.g., Internet access, mobile phones). The dumb pipe business is experiencing decreasing revenue per bit. CSPs know that this trend of diminishing profitability is unhealthy, and they are highly motivated to expand into new products (e.g., video).
Since the rise of the Internet, CSPs have seen Over The Top (OTT) services (Internet platformed services) thrive. OTT providers have even invaded the CSP’s spaces. While CSPs expanded into television and video services, OTT video services like Netflix and Hulu caused many customers to terminate their traditional television services. Customers prefer unbundled video streaming. This is especially true now that Disney Plus, ESPN+, HBO Max, and other premium video packages have become available à la carte (no longer exclusively bundled with television service). Unbundling of video services is once again relegating CSPs to selling dumb pipes, which undermines their efforts to expand revenues up the value chain.
CSPs have stodgy business models, because they are afraid of competition further eating into their revenue. CSPs suffer from their inability to formulate new product strategies to better monetize 5G investments. Technical features like network slicing, low latency, higher reliability, low power, high bandwidth, expanded radio spectrum offer possibilities for innovative applications, but carriers have struggled to translate such potential into desirable products beyond the standard offerings for the already saturated market for mobile phone service with mobile data.
From Tom Nolle:
Other articles:
Beyond 5G mobile and fixed wireless features, CSPs also have ambitions of expanding revenues through Edge Computing and “carrier cloud”. CSPs view the construction of their own cloud infrastructure in their own data centers as a core competency that is strategically important to the operation of the Network Functions that provide their communications services over their own network infrastructure.
Again, from Tom Nolle:
CSPs have ambitions to offer products to their customers based on carrier cloud, but they suffer from competition from hyperscalers (AWS, Microsoft Azure, Google Cloud Platform, Oracle, IBM). They aim to leverage their own data centers to provide cloud services for Edge Computing at the provider edge, believing that low latency in the last mile to the customer will offer performance advantages to certain types of services. Unfortunately, there is no evidence that such an advantage exists for CSPs. Performance sensitive components would likely need to be deployed at the customer edge in close proximity to the customer’s devices (such as for near real-time control of industrial processes). For all other types of services, it is difficult to see how regional CSPs can compete on price, scale, and reach against hyperscalers, who have global reach and performance characteristics that are not materially disadvantageous for those use cases. If customers need the performance, they will need computing at the customer edge. Otherwise, when their requirements are less stringent, public cloud infrastructure from hyperscalers is sufficient and economically advantageous.
CSPs must become more open to transforming their business models to find better revenue opportunities. They should look to Apple’s market success as one example of how to think differently. Apple forged a lucrative business model based on their iPhone and iOS ecosystem by taking a 30% cut of third party revenues earned by distributing applications through the Apple App Store. Because the potential for applications and in-app purchases is unbounded, the opportunities are enormous for Apple to earn revenues based on the innovations and work of innumerable third-parties using Apple’s platform. This is proven out by Apple’s incredible financial performance since launching this ecosystem.
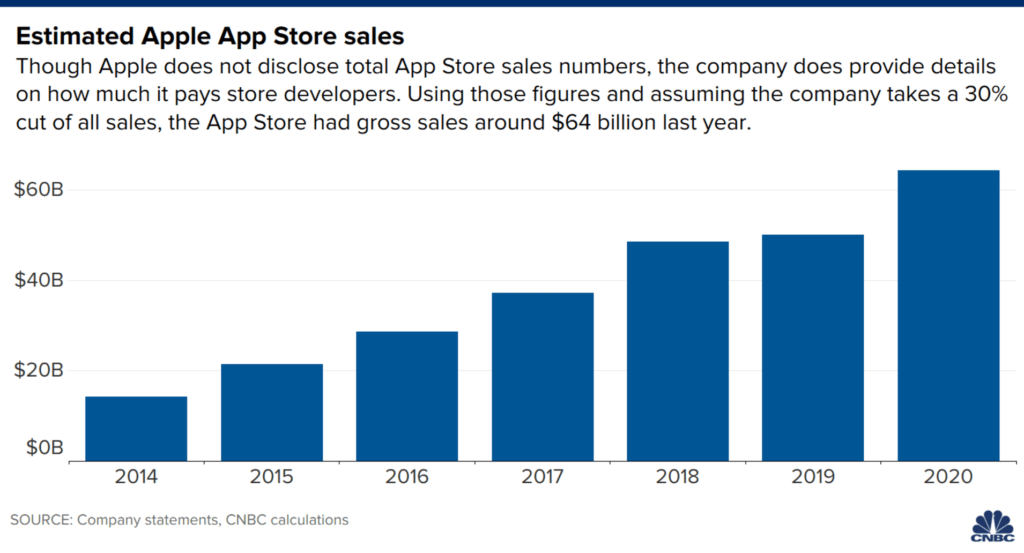
CSPs should look to where their own businesses have strengths and advantages. CSPs have a large and established customer base, who entrusts the carrier to take automatic payments every month. That kind of trust relationship and reliable revenue stream is precious. Carriers have not learned to monetize that relationship with OTT service partners or extend such relationships to third parties, as Apple does. One of the biggest impediments to online businesses converting sales for digital subscriptions is the resistance among customers to trust the business enough to create an account and authorize their payment card for automatic recurring payments. That lack of trust is an enormous barrier for most businesses. CSPs can leverage their advantage in Carrier billing to enable micropayments and easier monetization of third party services through the carrier’s infrastructure, billing, and payment platforms. This would enable CSPs to apply Apple’s business model to charge third party services a percentage of subscription fees by owning the customer relationship and the monetization of those third party services.
Let’s explore a concrete scenario to illustrate this point. As a customer of online digital services, each of us has routinely been the victim of multiple unscrupulous vendors. One crooked technique these vendors employ is to be unresponsive to termination requests for subscriptions that have recurring monthly payments automatically charged to a payment card. Sometimes such paid subscriptions are opted in by misleading a customer to try a free introductory offer. Often, intervention from the bank or payment card company is required as a remedy. These kinds of costly and upsetting incidents ruin it for all online digital services, because customers become wary of authorizing payments for any business whose reputation is unknown. Every time a customer shares their payment card information with another vendor, it is a calculated risk that the vendor could be unscrupulous or that the payment card information can be stolen by a data breach (hacking). After being burned, most people would be extremely hesitant to subscribe to a dozen low cost ($0.99 per month) content providers (i.e., magazines, journals, newspapers, etc.), each taking payments separately.
However, for a customer already being charged $200 per month by a CSP for their family’s multiple mobile phone and data services, adding an extra twelve $0.99 charges to their bill (an increase of less than 6%) with the peace of mind knowing that the carrier’s billing dispute and adjustment processes are reputable, friendly, and reliable is a comfortable commitment to enroll in. Now, imagine every product company taking advantage of this easy entry into the market for digital subscriptions, where they would otherwise have found the barrier to entry too daunting. You will see connected running shoes, connected tennis rackets, connected exercise equipment, connected vehicle dash cameras, connected home security cameras, connected home appliances, connected irrigation systems, connected pool circulation systems, connected everything become viable market opportunities for the smallest (and most innovative and entrepreneurial) of vendors. If CSPs bundled monetization with access to their 5G capabilities and their Edge Computing resources for a cut of the third party service’s revenues, that arrangement becomes even more attractive to innovative and entrepreneurial startups who may build the next killer app that no CSP could dream of themselves—and that would be impossible to nurture into existence through partnerships.
For CSPs who envision that the Internet of Things (IoT) will provide new revenue streams in high volumes, they must realize that for things to be connected to the Internet in an economical way, the digital services associated with those things must be monetizable easily and with low barrier to entry. For there to be sufficient uptake, not only do ordinary physical things in everyone’s every day lives need to be connected, but it must be inexpensive and convenient. Technical capabilities, convenience, and low cost come about by leveraging the CSP’s infrastructure, services, monetization platform, and established relationship with the customer base.
As a stodgy incumbent, a CSP is resistant to revamping how they do business. Their belief in their products is entrenched. They believe their own role in the market is entrenched. Incumbency and entrenchment are impediments to transforming their business. So long as CSPs cling to the belief that they must defend their declining revenue-per-bit dumb pipe business against OTT services, CSPs will not be motivated to engage in transformation. They need to understand that their advantage is not in dumb pipes. Their advantage is in owning strong customer relationships that can be monetized on behalf of third party services that are unbounded in potential revenue opportunities. Digital services want to receive payments from subscribers, and CSPs can broker this through their own reputable, ethical, and trust-worthy billing and payments platform.
CSPs must move away from primarily selling dumb pipes. They should re-orient the business to enable an ecosystem that uses the CSP’s infrastructure and platform to sell digital services from all vendors to the installed base of loyal customers. This will open up unbounded opportunities for passive income as all the risk to develop innovative new products based on OTT services is borne by third party digital service providers, while the CSP reaps the rewards of their use of the CSP’s ecosystem.
Observation: management is obsessed with assessing all kinds of risk and their mitigations. This includes technical risk, financial risk, schedule risk, market risk, security risk, and others. This typically does not include bus factor.
One of the biggest risks is the concentration of knowledge and expertise in too few individuals. This is known as bus factor. How many teams measure and report on bus factor, and actively mitigate the risk of bus factor falling to 1?







